4 BB Sözdizimi ve Temel Veri Türleri
İçindekiler4.1 Sözdizimi
Bu bölümde bütün BB sürümleri için ortak olan dilbilgisi kuralları (ve ileriye uyumlu çözümleme kuralları) açıklanmıştır (BB2 dahil). BB'nin ileri sürümlerinde başka sözdizimsel kurallar eklenecek olsa bile bu temel sözdizimine uyumluluk sağlanacaktır.
Burada bahsedilenler uyulması gerekli türden belirtimlerdir. Ayrıca BB2 Dilbilgisi Kuralları bölümündeki uyulması zorunlu dilbilgisi kurallarıyla bütünleşirler.
4.1.1 Dizgeciklere Ayırma
BB'nin tüm aşamaları (1. aşama, 2. aşama ve ileri aşamalar) aynı çekirdek sözdizimini kullanır. Böylece, bir kullanıcı arayüzünün (KA) yazıldığı sırada henüz mevcut olmayan bir BB aşamasına göre yazılmış bir biçembendi (tamamını anlamasa bile) çözümleyebilmesi sağlanmış olur. Tasarımcılar bu özelliği, BB'nin son aşamasındaki özellikleri denerken eski KA'larda da çalışabilecek biçembentleri yazmak için kullanabilirler.
Sözdizimsel seviyede BB biçembentleri peşpeşe dizilmiş dizgeciklerden oluşur. BB2 için bu dizgeciklerin listesi aşağıdadır. Tanımlarda Lex-vari düzenli ifadeler kullanılmıştır. ISO 10646 karakter gönderimleri için sekizlik kodlar kullanılmıştır ([ISO/IEC 10646]). Lex'deki gibi, çok sayıda eşleşme varlığında dizgeciği en uzun eşleşme belirler.
| Tanım Terimi | Tanım |
|---|---|
| ÖzAd | {ident} |
| @Sözcük | @{ident} |
| Dizge | {string} |
| Diyez | #{name} |
| Sayı | {num} |
| YüzdeDeğeri | {num}% |
| Boyutlar | {num}{ident} |
| URI | url\({w}{string}{w}\)|url\({w}([!#$%&*-~]|{nonascii}|{escape})*{w}\) |
| UnicodeAralığı | U\+[0-9A-F?]{1,6}(-[0-9A-F]{1,6})? |
| AçkBaşEtk | <!-- |
| AçkBitEtk | --> |
| ; | ; |
| { | \{ |
| } | \} |
| ( | \( |
| ) | \) |
| [ | \[ |
| ] | \] |
| B | [ \t\r\n\f]+ |
| Açıklama | \/\*[^*]*\*+([^/][^*]*\*+)*\/ |
| İşlevBaşı | {ident}\( |
| BoşlukluEşlem | ~= |
| TireliEşlem | |= |
| Ayraç | Ne bir tek tırnak ne bir çift tırnak ne de yukarıdaki kurallarla eşleşen bir karakterdir |
Yukarıda kaşlı ayraçların ({}) içinde belirtilen makroların tanımları aşağıdadır:
| Makro | Tanım |
|---|---|
| ident | {nmstart}{nmchar}* |
| name | {nmchar}+ |
| nmstart | [a-zA-Z_]|{nonascii}|{escape} |
| nonascii | [^\0-\177] |
| unicode | \\[0-9a-f]{1,6}[ \n\r\t\f]? |
| escape | {unicode}|\\[ -~\200-\4177777] |
| nmchar | [a-zA-Z0-9-_]|{nonascii}|{escape} |
| num | [0-9]+|[0-9]*\.[0-9]+ |
| string | {string1}|{string2} |
| string1 | \"([\t !#$%&(-~]|\\{nl}|\'|{nonascii}|{escape})*\" |
| string2 | \'([\t !#$%&(-~]|\\{nl}|\"|{nonascii}|{escape})*\' |
| nl | \n|\r\n|\r|\f |
| w | [ \t\r\n\f]* |
BB'nin temel sözdizimi aşağıdadır. Devamındaki bölümlerde nasıl kullanılacağı açıklanmıştır. BB2 Dilbilgisi Kuralları bölümündeki dilbilgisi kuralları BB'nin 2. aşamasına daha yakın olup daha ayrıntılı tanımlanmıştır.
biçembent ::= [ AçkBaşEtk | AçkBitEtk | B | yönerge ]*
yönerge ::= kural_kümesi | @-kuralı
@-kuralı ::= @-Sözcük B* terim* [ blok | ';' B* ]
blok ::= '{' B* [ terim | blok | @-Sözcük B* | ';' ]* '}' B*
kural_kümesi ::= seçici? '{' B* bildirim? [ ';' B* bildirim? ]* '}' B*
seçici ::= terim+
bildirim ::= Nitelik ':' B* değer
değer ::= [ terim | blok | @-Sözcük B* ]+
terim ::= [ ÖzAd | Sayı | YüzdeDeğeri | Boyutlar | Dizge | Ayraç
| URI | Diyez | UnicodeAralığı | BoşlukluEşlem | İşlevBaşı
'(' terim* ')' | TireliEşlem | '(' terim* ')'
| '[' terim* ']' ] B*Açıklama dizgecikleri dilbilgisi içinde yer almaz (okunabilir kılmak için), ancak bu dizgecikler diğer dizgecikler arasında her yerde istenen sayıda yer alabilirler.
Yukarıdaki sözdizimi tanımları içinde yer alan B karakterleri boşluk karakterlerini ifade eder. Boşluk karakterleri, sadece "boşluk" (Unicode kodu 32), "sekme" (9), "satırsonu" (10), "satırbaşı" (13) ve "sayfa ileri" (12) karakterlerini içerebilir. Diğer boşluk benzeri Unicode karakterleri ("em-boşluk" (8195) and "simgesel boşluk" (12288) gibi), boşluk karakterlerinden sayılmazlar.
4.1.2 Anahtar Sözcükler
Anahtar sözcükler betimleyici biçimindedirler ve tırnaklar arasında ("..." veya '...') yazılamazlar. Bu bakımdan,
red
bir anahtar sözcük olarak ele alınırken,
"red"
herhangi bir dizge olarak ele alınır. Diğer kuraldışı örnekler:
width: "auto"; border: "none"; font-family: "serif"; background: "red";
4.1.3 Karakterler ve Harf Büyüklüğü
Aşağıdaki kurallara daima uyulur:
Tüm BB biçembentleri, BB denetimi altında olmayan bölgeler hariç, harf büyüklüğüne duyarsızdır. Örneğin, HTML "id" ve "class" özniteliklerinin harf büyüklüğüne duyarlı değerleri ile yazıtipi isimleri ve tanım-yerleri bu belirtimin kapsamı dışındadır. Özellikle, HTML'deki eleman isimleri harf büyüklüğüne duyarsızken XML ve XHTML'de duyarlı oluşuna dikkat ediniz.
BB2'de, betimleyiciler (eleman isimleri, sınıflar ve seçicilerdeki ID'lar dahil) [_A-Za-z0-9-] karakterleriyle ISO 10646 karakterlerinden 161. ve sonrakileri içerebilir; bir tire imi veya bir rakamla başlayamazlar. Ayrıca öncelenmiş karakterleri ve sayısal kodlarıyla belirtilmek suretiyle bütün ISO 10646 karakterlerini içerebilirler (sonraki maddeye bakınız). Örneğin, "B&W?" betimleyicisi "B\&W\?" veya "B\26 W\3F" olarak da yazılabilir..
Unicode ile ISO 10646 birebir eşdeğerdir (bkz, [Unicode] ve [ISO/IEC 10646]).
BB2'de, bir tersbölü (\) karakteri üç tür karakter öncelemi belirtir.
İlki, bir dizgenin içinde, tersbölü karakteri satırın sonundaysa, yani tersbölü karakterinden hemen sonra satırsonu karakteri varsa, iki karakterde yoksayılır (fiziksel satıra sığmayan tek satırlık uzun bir dizge durumu).
İkincisinde, özel BB karakterlerinin anlambilgisini yokeder (karakteri sıradanlaştırır). Bir karakter (onaltılık rakamlar hariç), özel anlamını ortadan kaldırmak için bir tersbölü karakteri ile öncelenebilir (karakterin önüne \ konur). Örneğin
"\""dizgesi tek bir tane çift tırnak karakterinden oluşur. Biçembent önişlemcilerinin bu tersbölü karakterlerini, biçembendin anlamının değişmemesi için biçembentten kaldırmamaları gerekir.Üçüncüsünde, tersbölü öncelemleri yazarların belgeye kolayca yerleştiremedikleri karakterleri kodlamalarını sağlar. Bu durumda tersbölü karakterinden sonra ISO 10646 ([ISO/IEC 10646]) karakterinin numarasını belirtmek üzere en fazla altı tane onaltılık rakam [0-9a-f] gelebilir. Eğer karakter kodundan hemen sonra onaltılık rakam olabilecek bir harf veya rakam geliyorsa, kodun açıkça belirlenebilmesinin sağlanması gerekir. Bu iki yolla yapılabilir:
Araya bir boşluk (veya herhangi bir boşluk karakteri) yerleştirerek: "&B" için "\26 B" gibi. Bu durumda, kullanıcı arayüzlerinin bir satırsonu/satırbaşı çiftini (U+000D/U+000A) tek bir boşluk karakteri olarak ele alması gerekir.
Tam altı tane onaltılık rakam yazarak: "&B" için "\000026B" gibi.
Aslında bu iki yöntem birleştirilebilir. Onaltılık önceleme sonrası sadece bir boşluk karakteri yoksayılır. Burada, önceleme dizisinden sonraki "asıl" boşluğun kendisinin ya öncelenmiş olması ya da bir boşluk çifti olması gerektiğine dikkat ediniz.
Tersbölü öncelemleri daima ya bir betimleyicinin ya da dizgenin parçası kabul edilirler (yani, "{" bir noktalama imi olsa bile "\7B" değildir ve "\32"'ye bir sınıf isminin başında izin verilir ama "2"'ye izin verilmez).
4.1.4 Yönergeler
Bir BB biçembendi, hangi aşamadan olursa olsun, bir yönerge listesinden oluşur (yukarıdaki dilbilgisine bakın). İki çeşit yönerge vardır: @-kuralı ve kural kümesi. Yönergelerin çevresinde boşluk karakterleri yer alabilir.
Bu belirtimde "hemen önce" ve "hemen sonra" ifadeleri arada bir boşluk karakteri veya açıklama yer almadığı anlamına gelecektir.
4.1.5 @-Kuralları
@-kuralları bir @-Sözcük ile, yani bir @ karakterinden hemen sonra gelen bir betimleyici ile başlar (@import, @page gibi).
Bir @-kuralı bir noktalı virgül (;) veya bir Blok ile sonlanan (hangisi önce gelirse) bir şeylerden oluşur. Bir BB kullanıcı arayüzü bilinmeyen bir @-kuralı saptadığında bu @-kuralını bir bütün olarak yoksaymalı ve çözümleme işlemine devam etmelidir.
BB2 kullanıcı arayüzleri bir blok içinde kalan veya tüm kural kümelerinden önce yer almayan bir @import kuralını yoksaymalıdır.
- Örnek:
- Varsayalım, bir BB2 çözümleyici şöyle bir biçembente rastlamış olsun:
@import "subs.css"; H1 { color: blue } @import "list.css";İkinci
@importBB2'ye göre kuraldışıdır. BB2 çözümleyici @-kuralını tamamen yoksayarak biçembendi şöyle ele alır:@import "subs.css"; H1 { color: blue }
- Örnek:
- Bu örnekte, ikinci
@importkuralı, bir@mediabloku içinde yer aldığından geçersizdir.@import "subs.css"; @media print { @import "print-main.css"; BODY { font-size: 10pt } } H1 {color: blue }
4.1.6 Bloklar
Bir Blok bir sol kaşlı ayraç ({) ile başlar ve sağ kaşlı ayraçta (}) sona erer. Arada, daima eşleşen çiftler halinde yer alması gereken ve iç içe kullanılabilen parantezler (( )), köşeli ayraçlar ve kaşlı ayraçlar ({ }) hariç her karakter yer alabilir. Tek ve çift tırnak imlerinin de eşleşen çiftler halinde yer alması gerekir ve bunlar arasında kalan karakterler bir dizge olarak çözümlenir. Dizgenin sözdizimsel tanımı için yukarıya Dizgeciklere Ayırma bölümüne bakınız.
- Örnek:
- Burada bir blok örneği verilmiştir. Çift tırnaklar arasına alınmış sağ kaşlı ayracın bloku başlatan kaşlı ayraçla eşleşmeyeceğine ve ikinci tek tırnağın bir öncelenmiş karakter olarak ilk tek tırnakla eşleşmeyeceğine dikkat ediniz:
{ bakusta: "}" + ({7} * '\'') }Bu kural BB2 için geçersizdir, fakat yukarıda tanımlandığı gibi o yine de bir bloktur.
4.1.7 Kural kümeleri, bildirim blokları ve seçiciler
Bir kural kümesi ("kural" dendiği de olur) ardından bir blok gelen bir seçiciden oluşur.
Bir bildirim bloku ({}-bloku dendiği de olur) bir sol kaşlı ayraç ({) ile başlar ve sağ kaşlı ayraçta (}) sona erer. Arada, sıfır veya daha fazla sayıda noktalı virgül ayraçlı bildirimler yer almalıdır.
Bir seçici (ayrıca, Seçiciler bölümüne de bakınız) bloku başlatan ilk kaşlı ayraca kadar (onu içermeksizin) olan şeylerden oluşur. Bir seçici daima bir {}-bloku ile birlikte görünür. Bir kullanıcı arayüzü bir seçiciyi çözümleyemediği takdirde (bir BB2 biçembendi olmayabilir), seçiciyi {}-bloku ile birlikte yoksaymalıdır.
BB2, virgül (,) imine seçiciler içinde özel bir anlam atfeder. Bununla birlikte, BB'nin ileri sürümlerinde virgülün başka bir anlam taşıyıp taşımayacağı bilinmediğinden seçicide bir hata saptandığı takdirde, seçicinin kalanı BB2 için kabul edilebilir görünse bile yönergenin tamamı yoksayılmalıdır.
- Örnek:
- Bir BB2 seçicisinde "&" geçerli bir dizgecik olmadığından, bir BB2 kullanıcı arayüzünün örnekteki
<h3>elemanının içeriğine kırmızı rengi uygulamaksızın ikinci satırı yoksayması gerekir:h1, h2 {color: green } h3, h4 & h5 {color: red } h6 {color: black }
- Örnek:
- Burada daha karmaşık bir örneğe yer verilmiştir. Kaşlı ayraçların ilk iki çifti bir dizgenin içindedir ve seçicinin sonu imlenmemiştir. Bu, geçerli bir BB2 yönergesidir.
p[example="public class foo\ {\ private int x;\ \ foo(int x) {\ this.x = x;\ }\ \ }"] { color: red }
4.1.8 Bildirimler ve nitelikler
Bir Bildirim ya boştur ya da sırayla bir Nitelik, bir ikinokta (:) imi ve bir değerden oluşur. Bunların her birinin etrafında boşluk karakterleri yer alabilir.
Seçicilerin çalışma yönteminden dolayı, aynı seçici için bildirimler noktalı virgül (;) ayraçlı olarak gruplanabilir.
- Örnek:
- Bu bakımdan, bu kurallarla:
h1 { font-weight: bold } h1 { font-size: 12pt } h1 { line-height: 14pt } h1 { font-family: Helvetica } h1 { font-variant: normal } h1 { font-style: normal }bu eşdeğerdir:
h1 { font-weight: bold; font-size: 12pt; line-height: 14pt; font-family: Helvetica; font-variant: normal; font-style: normal }
Bir nitelik bir betimleyicidir. Değerde her karakter yer alabilir, fakat parantezler ("( )"), köşeli ayraçlar ("[ ]"), kaşlı ayraçlar ("{ }"), tek (') ve çift (") tırnaklar çiftler halinde yer almalı ve dizgelerin içinde yer almayan noktalı virgül (;) imleri tersbölü ile öncelenmelidir. Parantezler, köşeli ve kaşlı ayraçlar iç içe olabilirler. Tırnaklar arasında kalan karakterler bir dizge olarak çözümlenir.
Değer sözdizimleri her nitelikte ayrı ayrı belirtilmiştir, fakat her durumda, değerler Betimleyiciler, Dizgeler, Sayılar, Uzunluklar, YüzdeDeğerleri, TanımYerleri, Renkler, Açılar, Süreler ve Frekanslardan oluşur.
Bir kullanıcı arayüzünün nitelik ismi veya değeri geçersiz bir bildirimi yoksayması gerekir. Her BB2 niteliğinin kabul ettiği değerler üzerinde kendine özgü sözdizimsel ve anlambilimsel kısıtlamaları vardır.
- Örnek:
- Bir BB2 çözümleyicinin şöyle bir biçembende rastladığını varsayalım:
h1 { color: red; font-style: 12pt } /* Geçersiz değer: 12pt */ p { color: blue; font-vendor: any; /* Geçersiz nitelik: font-vendor */ font-variant: small-caps } em em { font-style: normal }Birinci satırdaki ikinci bildirim geçersiz bir değer (12pt) içermektedir. İkici satırın ikinci bildirimi ise tanımsız bir nitelik ismi ('font-vendor') içermektedir. BB2 çözümleyici bu bildirimleri yoksayarak biçembendi şuna indirgeyecektir:
h1 { color: red; } p { color: blue; font-variant: small-caps } em em { font-style: normal }
4.1.9 Açıklamalar
Açıklamalar /* karakterleri ile başlar, */ karakterleri ile biter. Dizgecikler arasında her yerde bulunabilirler ve içerikleri yoksayılır. Açıklamalar iç içe olamazlar..
BB ayrıca SGML açıklamalarının ayraçlarına da (<!-- ve
-->) belli yerlerde izin verir, fakat bunlar BB açıklama ayracı değillerdir. HTML 3.2 öncesi kullanıcı arayüzlerinden HTML belgelerde (<style> elemanında) bulunan biçembent kurallarını gizlemek için izin verilmiştir. Bu konuda daha fazla bilgi için HTML 4.0 belirtimine ([HTML40]) bakınız.
4.2 Çözümleme hatalarının eldesi ile ilgili kurallar
Bazı durumlarda kullanıcı arayüzlerinin bir geçersiz biçembent bölümünü yoksayması gerekir. Bu belirtim yoksayma işlemini kullanıcı arayüzünün geçersiz bir biçembent parçasını (başını ve sonunu bularak) çözümlemesiyle ilgili bir durumu anlatmak için kullanır.
İleride yeni niteliklerin veya mevcut niteliklere yeni değerlerin eklenebilmesini sağlamak üzere, kullanıcı arayüzlerinin aşağı belirtilen senaryolara rastladıklarında yine aşağıdaki belirtilen kurallara uymaları gerekir:
- Bilinmeyen nitelikler
- Kullanıcı arayüzlerinin bilinmeyen nitelik içeren bir bildirimi yoksayması gerekir.
- Örnek:
h1 { color: red; rotation: 70minutes }böyle bir biçembenti kullanıcı arayüzü şundan ibaretmiş gibi ele alacaktır:
h1 { color: red }
- Kuraldışı değerler
- Kullanıcı arayüzlerinin kuraldışı değer içeren bir bildirimi yoksayması gerekir.
- Örnek:
img { float: left } /* BB2 için doğru */ img { float: left here } /* "here" birfloatdeğeri değildir */ img { background: "red" } /* BB2'de anahtar sözcükler */ /* tırnak içine alınamazlar */ img { border-width: 3 } /* Uzunluk değerleri için birim */ /* belirtmek gerekir */Bir BB2 çözümleyici ilk kuralı işleme sokup diğerlerini yoksaymalıdır. Bu takdirde biçembent şuna indirgenmiş olur:
img { float: left } img { } img { } img { }Daha ileri bir BB belirtimine uyumlu bir kullanıcı arayüzü diğer kuralları da kabul ediyor olabilir.
- Geçersiz @-Sözcükler
- Kullanıcı arayüzlerinin geçersiz bir @-sözcüğünü bir blok ({...}) başlangıcına veya olası bir sonlandırıcı noktalı virgül (;) imine kadar (im dahil) (hangisine önce rastlanırsa) yoksayması gerekir.
- Örnek:
@three-dee { @background-lighting { azimuth: 30deg; elevation: 190deg; } h1 { color: red } } h1 { color: blue }@three-dee @-kuralı BB2'nin bir parçası değildir. Dolayısıyla, @-kuralının tamamı (üçüncü sağ kaşlı ayraca kadar, ayraç dahil) yoksayılır. Bir BB2 kullanıcı arayüzü bunu yoksayarak biçembendi şuna indirger:
h1 { color: blue }
4.3 Değerler
4.3.1 Tam ve gerçel sayılar
Bazı değerler tamsayı veya gerçel sayı türünde olabilir. Tam ve gerçel sayılar sadece onluk tabanda gösterilebilir. Bir tamsayı "0" ile "9" arasında bir veya daha fazla rakam içerebilir. Bir gerçel sayı ise, bir tamsayı olabileceği gibi, aralarında tek bir nokta (.) bulunan iki veya daha fazla rakamdan oluşabilir. Tam ve gerçel sayıların önüne işaret belirten bir "+" veya "-" imi konmuş olabilir.
Bazı nitelikler bir tam veya gerçel sayıyı belli bir değer aralığında kabul edebilir, sıklıkla da bu negatif bir değer olmamakla sınırlıdır.
4.3.2 Uzunluklar
Uzunluklar yatay veya düşey ölçü belirtirler.
Bu belirtimde bir uzunluk değerinin biçimi bir sayıdan (ondalık nokta içersin/içermesin) hemen sonra bir birim belirtecinin (px, deg gibi) yer alması şeklindedir. '0' değerinden sonra bir birim belirtecinin bulunması zorunlu değildir.
Bazı nitelikler negatif Uzunluk değerlerine izin verse de biçimleme modeliyle ilgili sorunlara yol açabilir ve dolayısıyla gerçeklenime özgü sınırlamalar bulunabilir. Eğer bir negatif değer desteklenemiyorsa, desteklenen en yakın değere dönüştürülmesi gerekir.
İki tür uzunluk birimi vardır: göreli ve mutlak. Göreli uzunluk birimleri başka bir uzunluk niteliğine göreli bir uzunluk belirtir. Göreli birimler kullanılan biçembentlerde bir ortam bir diğeri ile kolayca ölçeklenebilir (örneğin bilgisayar ekranı ile bir laser yazıcı arasındaki oranlama gibi)).
Göreli birimler şunlardır:
- em: geçerli yazıtipinin
font-sizedeğeri - ex: geçerli yazıtipinin x-height değeri
- px: görüntüleme aygıtında geçerli benekler için
h1 { margin: 0.5em } /* em */
h1 { margin: 1ex } /* ex */
p { font-size: 12px } /* px */
em birimi, kullanıldığı elemanın font-size niteliğinin hesaplanmış değerine eşit bir birimdir. Ancak, font-size niteliğinin kendisi için belirtilen değerin birimi olarak em bunu dışındadır; bu durumda, ebeveyn elemanın yazıtipi boyutuna görelilik sözkonusudur. Birim hem genişlik hem de yükseklik belirtmek için kullanılabilir. (Matbaacılıkla ilgili metinlerde bu birimden dördül genişlik diye bahsedildiği de olur.)
ex birimi, geçerli yazıtipinin x-height değerine göre tanımlanır. "x-height" (x-yükseklik) denmesinin sebebi, çoğunlukla küçük "x" harfinin yüksekliğine eşit olmasındandır. Bununla birlikte, ex birimi küçük "x" harfi içermeyen yazıtipleri için bile tanımlıdır.
h1 { line-height: 1.2em }kuralı, <h1> elemanının satır yüksekliğinin kendi yazıtipinin yüksekliğinden %20 daha yüksek olacağı anlamına gelir. Diğer taraftan,
h1 { font-size: 1.2em }kuralı, <h1> elemanının yazıtipi yüksekliği için elemanın ebeveyninin yazıtipi yüksekliğinden %20 daha büyük bir yükseklik belirtir.
em ve ex birimleri belge ağacının kökü (HTML için <html>) için belirtildiği takdirde, niteliğin ilk değeri birimin değeri olur.
Benek birimleri genellikle görüntüleme aygıtının (ekran gibi) çözünürlüğüne bağlıdır. Eğer çıktı aygıtının benek yoğunluğu (genelde inç başına benek sayısı [dpi] olarak belirtilir) sıradan bir ekranın benek yoğunluğundan çok farklıysa, kullanıcı arayüzünün gerekli ayarlamaları yapması gerekir. Benek yoğunluğu 96dpi olan bir aygıt üzerinde ve okuyucunun kol mesafesinde bir beneğin görüş açısının ölçek benek olarak alınması önerilmektedir. Normal kol uzurluğu 28 inç alındığında bu açı yaklaşık 0,0213 derece olmaktadır.
Bu durumda, kol mesafesinden okumak için, 1px yaklaşık 0,26 mm'ye denk düşmektedir (1/96 inç). Görüntüleme aygıtı bir lazer yazıcı olduğunda, kol mesafesinden daha küçük bir okuma mesafesi (55 cm, 21 inç) kullanılır ve dolayısıyla 1px yaklaşık 0,21 mm olur. 300 dpi'lik bir yazıcı için bu yaklaşık 3 noktaya (0,25 mm); 600 dpi'lık bir yazıcı için ise yaklaşık 5 noktaya denk düşer.
Aşağıdaki iki resimde bir beneğin boyutuna görüş mesafesinin ve aygıt çözünürlüğünün etkisi gösterilmiştir. İlk resimde, 71 cm.lik (28 inç) okuma mesafesi 0,26 mm.lik bir benekle sonuçlanmaktayken, 3,5 m.lik bir okuma mesafesi için benek boyutu 1,4 mm olmaktadır.
İkinci resimde, düşük çözünürlüklü bir aygıt üzerindeki 1px2 lik bir alan tek bir nokta iken yüksek çözünürlüklü bir aygıtta aynı alanın 16 nokta kaplaması (400 dpi'lık lazer yazıcı için) resmedilmiştir.
Çocuk elemanlar ebeveynleri için belirtilmiş göreli değerleri değil, (genellikle) hesaplanmış değerleri miras alırlar.
- Örnek:
- Aşağıdaki kurallarda,
<h1>elemanı<body>elemanının çocuğu olduğundan<h1>elemanının hesaplanmıştext-indentdeğeri 45pt değil 36pt olacaktır.body { font-size: 12pt; text-indent: 3em; /* yani, 36pt */ } h1 { font-size: 15pt }
Mutlak uzunluk birimleri sadece çıktı ortamının fiziksel nitelikleri bilindiği takdirde yararlıdır. Mutlak birimler şunlardır:
- in: inç -- 1 inç = 2,54 cm
- cm: santimetre
- mm: milimetre
- pt: punto -- BB2 için 72 punto = 1 inç
- pc: pika -- 12 pika = 1 inç
h1 { margin: 0.5in } /* inç */
h2 { line-height: 3cm } /* santimetre */
h3 { word-spacing: 4mm } /* milimetre */
h4 { font-size: 12pt } /* punto */
h4 { font-size: 1pc } /* pika */Belirtilen uzunluk desteklenemediği takdirde, kullanıcı arayüzü asıl değer üzerinde yaklaşımda bulunmalıdır.
4.3.3 Yüzde Değerleri
Bir yüzdelik değerin bu belirtimdeki biçimi sırasıyla, isteğe bağlı bir işaret karakteri ('+' veya '-', '+' öntanımlıdır), bir sayı ve hemen ardından gelen bir yüzde iminden ('%') oluşur.
Yüzdelik değerler daima başka değerlere (uzunluk gibi) görelidir. Yüzdelik değerlere izin veren her nitelik ayrıca birer ölçü değeri de tanımlar. Değer aynı elemanın başka bir niteliği, üstsel elemanlardan birinin bir niteliği veya biçimleme bağlamından bir değer (bir taşıyıcı blok genişliği gibi) olabilir. Bir yüzdelik değer bir kök elemanın bir özniteliği için atandığında ve bazı niteliklerden miras alınan bir değere göre belirtildiğinde, hesaplanan değer için yüzdelik değerin çarpanı niteliğin ilk değeri olur.
Çocuk elemanlar ebeveynlerinden (genellikle) hesaplanmış değerleri miras aldıklarından, aşağıdaki örnekte, <p> elemanının çocukları line-height niteliğinin değeri olarak yüzdelik değeri (120%) değil, 12pt'luk değeri miras alacaklardır:
p { font-size: 10pt }
p { line-height: 120% } /* font-size'ın %120'si' */4.3.4 URL + URN = URI
URL'ler (Uniform Resource Locators - Tekbiçimli Özkaynak Konumlayıcı, bkz, [RFC3986] ve [RFC1808]) Genel Ağ üzerinde bir özkaynağın adresini belirtmekte kullanılırlar. Özkaynakları betimlemenin yeni yolu da URN (Uniform Resource Name - Tekbiçimli Özkaynak Adı) olarak bilinir. Bunların ikisine birden tanım-yeri denir (URI - Uniform Resource Identifier, Tekbiçimli Özkaynak Betimleyici, bkz, [URI]).
Tanım-yerlerinin değer türü olarak bu belirtimde tanım-yeri gösterimi kullanılacaktır. Tanım-yerlerini atamak için kullanılan işlevsel gösterim aşağıdaki örnekten de görüldüğü gibi url() biçimindedir:
body { background: url("http://www.bg.com/pinkish.gif") }Bir tanım-yeri biçimi sırayla, url( karakter dizisinden sonra isteğe bağlı olarak boşluk karakterleri, tek (') veya çift (") tırnak içine alınması isteğe bağlı olarak tanım-yerinin kendisi ve isteğe bağlı boşluk karakterlerinden sonra gelen bir )'den oluşur. Tırnak karakterlerinin ikisinin de aynı olması gerekir.
- Örnek:
- Tırnaksız bir örnek:
LI { list-style: url(http://www.redballs.com/redball.png) disc }
Parantezler, virgüller, boşluk karakterleri, tek ve çift tırnaklar bir tanım-yeri içinde yer aldıkları takdirde bir tersbölü ile öncelenmelidirler: \( \) \,
Tanım-yeri türüne bağlı olarak, yukarıdaki karakterleri [URI] belirtiminde açıklandığı gibi tanım-yeri öncelemleri olarak da yazmak mümkündür ("(" = %28, ")" = %29, vs.).
Bir özkaynağın mutlak konumuna bağlı olmayan uyarlanabilir biçembentlerin oluşturulması sırasında yazarlar göreli tanım-yerleri kullanabilirler. Göreli tanım-yerleri ([RFC1808] belirtiminde tanımlandığı gibi) bir temel tanım-yeri kullanılarak mutlak tanım-yerlerine dönüştürülürler. RFC 1808'in 3. bölümünde bu sürecin uyulması zorunlu algoritması tanımlanmıştır. BB biçembentleri için biçembendin temel tanım-yeri, kaynak belgenin mutlak tanım-yeri değildir.
- Örnek:
http://www.myorg.org/style/basic.css
tanım-yerine göre atanmış bir biçembentte şöyle bir kural olsun:
body { background: url("yellow") }Kaynak belgenin
<body>elemanının artalan resmihttp://www.myorg.org/style/yellow
adresinden alınacaktır.
Geçersiz veya kullanışsız tanım-yerlerinin elde ediliş yöntemi kullanıcı arayüzleri arasında değişiklik gösterebilir.
4.3.5 Sayaçlar
Sayaçlar betimleyicilerle ifade edilir. Bir sayaç değerine atıfta bulunmak için counter(betimleyici) veya counter(betimleyici, list-style-type) gösterimi kullanılır. Öntanımlı liste biçemi türü onluk sayı biçemidir (decimal).
Aynı isimde olup iç içe bir dizi oluşturan sayaçları ifade etmek için counter(betimleyici, dizga) veya counter(betimleyici, dizge, list-style-type) gösterimi kullanılır. Sayaçlarda iç içelik ve etki alanı bölümüne de bakınız.
BB2'de sayaç değerlerine sadece content niteliklerinden atıfta bulunulabilir. none değerinin bir olası list-style-type değeri oluşuna dikkat ediniz: counter(x, none) bir boş dizgeye karşılıktır.
- Örnek:
- Bu örnekte, bölümlerin (
<h1>) içinde yer alan paragrafları (<p>) numaralamakta kullanılan bir biçembende yer verilmiştir. Paragraflar romen rakamları ile numaralanmakta ve numaranın ardına bir nokta ve bir boşluk konmaktadır:p {counter-increment: par-num} h1 {counter-reset: par-num} p:before {content: counter(par-num, upper-roman) ". "}
Bir counter-reset'in etki alanında olmayan sayaçların kök elemandaki bir counter-reset tarafından 0 değeriyle başlatılmak zorunda oldukları varsayılır.
4.3.6 Renkler
Bir renk ya bir anahtar sözcüktür ya da sayısal bir KYM (Kırmızı-Yeşil-Mavi) belirtimidir..
Renklerin anahtar sözcükleri:
black,
silver, gray,
navy,
blue,
aqua,
teal,
purple,
fuchsia,
white,
lime,
green,
maroon,
red,
orange,
yellow,
olive. Bu 17 rengin KYM değerleri aşağıdaki gibidir. Bunların 16 tanesi (orange hariç) HTML 4.0'da tanımlanmıştır ([HTML40]).
- Çevirmenin notu:
- Bu resim, BB2.1 belirtiminin çalışma taslağından alıntıdır.
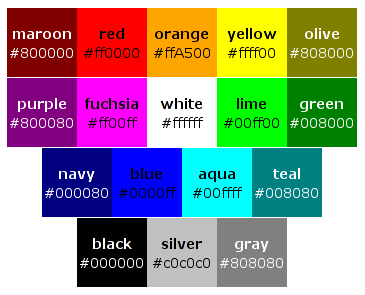
Bu renk anahtar sözcüklerine ilaveten kullanıcının çalışma ortamındaki belli nesneler tarafından kullanılan renklere karşı düşen anahtar sözcükler de belirtilebilir. Daha fazla bilgi için User preferences for colors bölümüne bakınız.
body {color: black; background: white }
h1 { color: maroon }
h2 { color: olive }KYB renk modeli sayısal renk belirtirken kullanılır. Bu örneklerin hepsi aynı rengi belirtir:
em { color: #f00 } /* #kym */
em { color: #ff0000 } /* #kkyymm */
em { color: rgb(255,0,0) }
em { color: rgb(100%, 0%, 0%) }Bir KYM değerinin biçimi onaltılık gösterimle şöyledir: bir '#' ile başlar ve hemen ardından ya üç ya da 6 hanelik bir onaltılık sayı gelir. Üç haneli KYM gösterimi (#kym) rakamların her biri yinelenerek (0 eklenerek değil) 6 haneli biçime (#kkyymm) dönüştürülür. Örneğin, #fb0, #ffbb00 olarak genişletilir. Böylece beyaz rengi (#ffffff) kısa gösterimle (#fff) ifade etmek mümkün olmaktan başka ekranın renk derinliğine bir bağımlılık olmaz.
Bir KYM değerinin biçimi işlevsel gösterimle şöyledir: 'rgb(' karakter dizisi ile başlar, birbirlerinden virgüllerle ayrılmış üç sayısal değerin ardından bir ')' ile sonlanır. Üç sayısal değer birer tamsayı olabilecekleri gibi yüzdelik değerlerde olabilirler ve bunların etrafında boşluk karakterleri bulunabilir. Tamsayı 255 değeri, 100% ve onaltılık gösterimle F veya FF değerine karşılıktır:
rgb(255,255,255) = rgb(100%,100%,100%) = #FFF
Tüm KYM renkleri sRGB renk uzayında belirtilirler (bkz, [SRGB]). Kullanıcı arayüzleri renkleri gösterirken asıllarına sadakat konusunda farklı davranabilirler, fakat sRGB kullanımı uluslararası standartlarla (bkz, [COLORIMETRY]) ilgili olarak renklerin olması gerekli renk değerleri için belirsizliği ortadan kaldıran, nesnel olarak ölçülebilen tanımlar sağlar.
Uyumlu kullanıcı arayüzleri, renk gösterme çabalarını bir gamma düzeltmesi uygulayarak düşük tutabilirler. sRGB, belirtilen görüntüleme koşulları altında 2.2'lik bir ekran gamması belirtir. BB'de belirtilmiş renkleri kullanıcı arayüzleri şöyle ayarlamalıdır: çıktı aygıtının "doğal" ekran gamması ile birlikte, 2.2'lik bir etkin ekran gamması üretilir. Ayrıntılar için Gamma düzeltmesi bölümüne bakınız. Bundan sadece BB'de belirtilen renklerin etkileneceği, örneğin resimlerin kendi renk bilgilerini taşıyacakları varsayılır.
Aygıtın renk tayfı dışında kalan değerler kırpılmalıdır: kırmızı, yeşil ve mavi değerleri aygıt tarafından desteklenen aralığın içine düşecek şekilde değiştirilmelidir. Sıradan bir CRT monitör için, aygıt renk tayfı sRGB ile aynı olduğunda aşağıdaki üç kural eşdeğerdir:
em { color: rgb(255,0,0) } /* tamsayı aralığı 0 - 255 */
em { color: rgb(300,0,0) } /* rgb(255,0,0) olacak şekilde kırpılır */
em { color: rgb(255,-10,0) } /* rgb(255,0,0) olacak şekilde kırpılır */
em { color: rgb(110%, 0%, 0%) } /* rgb(100%,0%,0%) olarak kırpılır */Diğer aygıtlar, örneğin yazıcılar sRGB için farklı bir tayfa sahiptirler; 0..255'lik sRGB aralığının dışında kalan bazı renkler (aygıt renk tayfı içinde kalanlar) gösterilebilecekken, 0..255'lik sRGB aralığının içinde kalan bazı renkler aygıt renk tayfının dışında kalarak kırpılabilecektir.
- Not:
- Renkler belgeye önemli miktarda bilgi ekleyebildiği ve onları daha okunabilir yaptığı halde renk körlüğü olan kullanıcılarda belli renk birleşimlerinin sorunlara yol açabileceğini lütfen dikkate alınız. Eğer bir artalan resmi veya rengi kullanıyorsanız, lütfen önalandaki renkleri de uygun değerlere ayarlayınız.
4.3.7 Açılar
Açı değerleri (metin içinde açı olarak geçer) işitsel biçembentlerde kullanılırlar..
Biçimleri, isteğe bağlı bir işaret karakterinden ('+' veya '-'; '+' öntanımlıdır) hemen sonra gelen bir sayıdan hemen sonra gelen bir açı birimi belirtecinden oluşur. Tıpkı uzunluklarda olduğu gibi 0 değeri için birim belirtilmeyebilir. '0deg' yerine basitçe '0' yazılabilir.
Açı birimi belirteçleri:
- deg: derece
- grad: grad
- rad: radyan
Açı değerleri negatif olabilir. 0-360 derecelik bir aralıkta kalacak şekilde kullanıcı arayüzleri tarafından normalleştirilirler. Örneğin, -10deg ile 350deg eşdeğerdir.
Örneğin bir dik açı '90deg' veya '100grad' ya da '1.570796326794897rad' olarak belirtilebilir.
4.3.8 Süreler
Zaman aralığı değerleri (metin içinde süre olarak geçer) işitsel biçembentlerde kullanılır..
Biçimleri, bir sayıdan hemen sonra gelen bir süre birimi belirtecinden oluşur. Tıpkı uzunluklarda olduğu gibi 0 değeri için birim belirtilmeyebilir. '0ms' yerine basitçe '0' yazılabilir.
Süre birimi belirteçleri:
- ms: milisaniye
- s: saniye
Süre değerleri negatif olamaz.
4.3.9 Frekanslar
Frekans değerleri (metin içinde frekans olarak geçer) işitsel biçembentlerde kullanılır.
Biçimleri, bir sayıdan hemen sonra gelen bir frekans birimi belirtecinden oluşur. Tıpkı uzunluklarda olduğu gibi 0 değeri için birim belirtilmeyebilir. '0Hz' yerine basitçe '0' yazılabilir.
Frekans birimi belirteçleri:
- Hz: Hertz
- kHz: kiloHertz
Frekans değerleri negatif olamaz.
Örneğin, 200Hz (veya 200hz) bir bas ses belirtirken 6kHz (veya 6khz) bir tiz ses belirtir.
4.3.10 Dizgeler
Dizgeler (metin içinde dizge olarak geçer) çift ya da tek tırnaklar arasına yazılır. Çift tırnaklar, çift tırnaklar içine yazılmış bir dizgede öncelenmiş ('\"' veya '\22' olarak) olmadıkça yer alamaz. Aynı şeyler tek tırnaklar için de geçerlidir ("\'" veya "\27" olarak öncelenirler).
"bu bir 'dizgedir'" "bu bir \"dizgedir\"" 'bu bir "dizgedir"' 'bu bir \'dizgedir\''
Bir dizge doğrudan bir satırsonu karakteri içeremez. Bir satırsonu karakterini bir dizge içinde belirtebilmek için "\A" öncelemi kullanılır (Onaltılık A rakamı Unicode'daki satır ileri karakterine karşılıktır, fakat BB'de satırsonu denmektedir.) Örnek için content niteliğinin tanımına bakınız.
Dizgeleri estetik kaygılar, vs. nedeniyle satırlara bölmek olasıdır, fakat böyle bir durumda satırsonu karakterinin kendisinin bir tersbölü (\) karakteriyle öncelenmesi gerekir. Örneğin aşağıdaki iki seçici tamamen aynıdır:
A[TITLE="a not s\
o very long title"] {/*...*/}
A[TITLE="a not so very long title"] {/*...*/}4.4 BB belge karakter kodlaması
Bir BB biçembendi Evrensel Karakter Kümesindeki [ISO/IEC 10646] karakterlerden oluşan bir dizidir. Aktarım ve saklama amacıyla, bu karakterler US-ASCII'deki karakterleri destekleyen bir karakter kodlaması ile kodlanmalıdır (ISO 8859-x, SHIFT JIS gibi). Karakter kümeleri ve karakter kodları ile ilgili iyi bir başlangıç olarak lütfen HTML 4.0 belirtimine ([HTML40], 5. fasıl) ve ayrıca XML 1.0 belirtiminin ([XML10]) 2.2 ve 4.3.3 bölümleri ile F ekine bakınız.
Bir biçembent bir belgenin (XML veya HTML gibi) içine gömüldüğünde, örneğin HTML'nin <style> elemanında veya 'style' özniteliğinde, biçembent belgenin bütününün karakter kodlamasını paylaşır.
Bir biçembent kendine ait ayrı bir dosyada bulunuyorsa, kullanıcı arayüzü bir belgenin karakter kodlamasını saptarken aşağıdaki önceliklere (en yüksekten en düşüğe) uyması gerekir:
Bir HTTP 'Content-Type' alanındaki 'charset' değergeci.
Atıf yapılan belgenin dil mekanizmaları (örn, HTML'de
<link>elemanının 'charset' özniteliği).
Bir @charset kuralı olsa olsa bir harici biçembentte görülebilir -- bir gömülü biçembentte bulunmamalıdır -- ve belgenin oldukça başlarında, kendinden önce bir karakter yer almayacak kadar başlarında yer almalıdır. @charset'in ardından karakter kodlamasının ismini belirtilir. İsim, [IANA]'da kayıtlı bir karakter kümesi ismi olmalıdır. Ayrıca, karakter kümelerinin tam listesi için [IANA-KARKÜM] belgesine bakınız. Örnek:
@charset "ISO-8859-1";
Bu belirtim kullanıcı arayüzlerinin desteklemesi gereken karakter kümeleri için zorlayıcı değildir.
@charset oluşumuna güvenmek, nasıl kodlanacağına dair tam bir bilgi olmadığından kuramsal olarak bir sorunmuş gibi görünür. Uygulamada ise, GenelAğ'da yaygın olarak kullanılan kodlamalar vardır: ASCII, UTF-16, UCS-4 gibi. Yani, sırf belgenin ilk baytına bakarak bir kullanıcı arayüzünün kodlama ailesini saptaması ve esas karakter kodlamasını tespit için @charset kuralını çözümleyecek yeterli bilgiyi edinmesi mümkündür.
4.4.1 Karakter Gönderimleri ve Karakter Öncelemleri
Bir biçembentte geçerli karakter kodlaması ile elde edilemeyen karakterlerin kullanılması gerekebilir. Bu karakterler, ISO 10646 karakterlerine gönderim yapacak şekilde öncelenmiş olarak yazılmalıdır. Bu öncelemler, HTML ve XML'deki sayısal karakter gönderimleri ile aynı amaca hizmet ederler ([HTML40], 5. ve 24. fasıllara bakınız).
Karakter önceleme mekanizması sadece birkaç karakter için bu yola başvurulacaksa kullanılmalıdır. Eğer bir belge çok fazla öncelem gerektiriyorsa, yazarlar belgeyi uygun bir kodlama ile kodlamalıdırlar (örneğin, belge Türkçe karakterler içeriyorsa yazar "ISO-8859-9" veya "UTF-8" kullanmalıdır).
Ara işlemcilerle farklı bir karakter kodlaması kullanılarak bu öncelemli diziler uygun kodlamanın bayt dizilerine dönüştürülebilir. Bu ara işlemciler özel anlamı olan ASCII karakterlerinin anlamlarını önceleme yaparak değiştirmemelidirler.
Uyumlu kullanıcı arayüzlerinin tüm Unicode karakterlerini tanıdıkları herhangi bir karakter kodlamasına doğru olarak eşleyebilmesi gerekir.
Örneğin, ISO-8859-1 (Latin-1) kodlamalı bir belge Yunan karakterlerini doğrudan içeremez: "κουρος" (Okunuşu: "kouros") biçembende "\3BA\3BF\3C5\3C1\3BF\3C2" dizgesi olarak yazılmalıdır.
- Not:
- HTML 4.0'da, sayısal karakter gönderimleri 'style' özniteliklerinde yorumlanırken,
<style>elemanlarında yorumlanmazlar. Bu dengesizlikten dolayı, yazarlara her iki alanda da BB karakter önceleme mekanizmasını kullanmalarını öneririz. Örneğin,<SPAN style="voice-family: D&#252;rst">...</SPAN>
yerine
<SPAN style="voice-family: D\FC rst">...</SPAN>
kullanılmasını öneririz.